
当前,大模型正加速走向端侧——AI手机、智能汽车、边缘网关纷纷尝试在本地运行7B甚至更大参数的模型。然而当前正处于混沌开天之初,这一进程并未收敛到统一的技术路径:模型架构百花齐放,量化方案五花八门,软件生态各自为营,加之端侧设备天然的应用场景高度分化,甚至连评估标准也尚未有一。在这样一个高度碎片化、快速演进的环境中股票开户配资,专用NPU若仅针对某一种模型或格式优化,极易陷入“发布即过时”的困境。
面对这种结构性的复杂,单纯堆砌算力已难以为继,真正的瓶颈在于:如何用一套统一的硬件架构,高效承载千变万化的端侧AI负载?
正是在这一背景下,安谋科技推出的“周易”X3 NPU IP,选择了一条截然不同的道路——以极致的通用性、可编程性和多精度灵活性为核心,构建一个能够“面向未来”的端侧AI算力底座,而非仅仅适配当下。
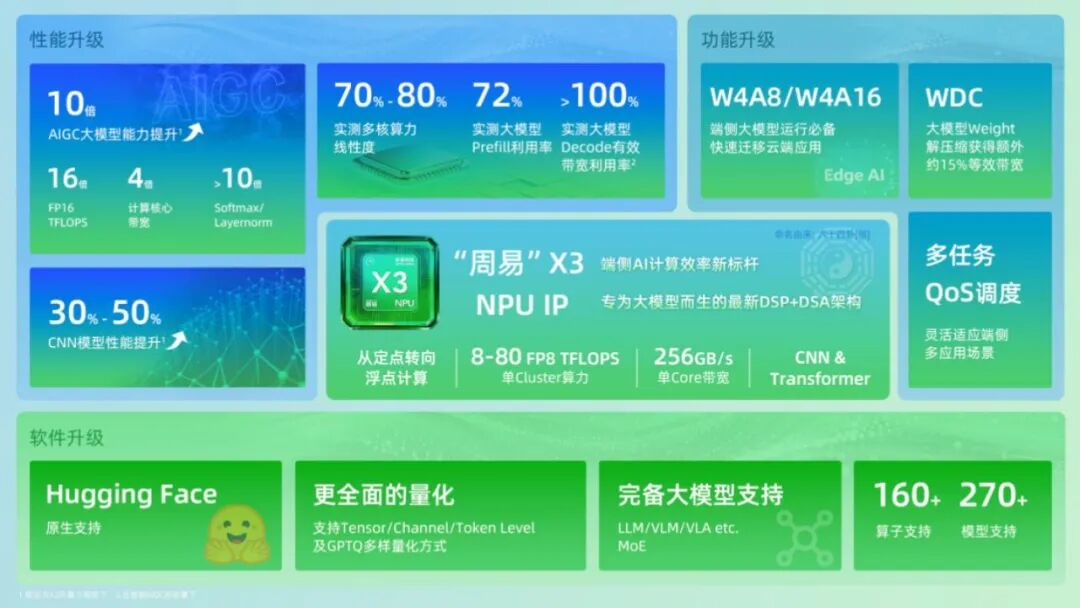
2025年11月13日,安谋科技正式发布其新一代NPU IP——“周易”X3。该产品基于专为大模型优化的全新“DSP+DSA”架构,兼顾CNN与Transformer模型的高效处理,并搭配易用性出色的“周易”NPU Compass AI软件平台,旨在为基础设施、智能汽车、移动终端和智能物联网四大领域提供强大的AI计算核心,树立端侧AI计算效率的新标杆,加速边缘与端侧AI的规模化落地。
“周易”X3架构解析:专为端侧大模型打造的DSP+DSA新范式
长期以来,移动端计算单元受限于功耗与面积约束,更多采用定点运算(如INT8/INT16)来提升能效比。然而,随着Transformer类大模型成为主流,尤其是生成式AI对高精度动态范围的需求激增,传统定点架构已难以满足复杂模型训练与推理中的数值稳定性要求。
“周易”X3从定点计算转向浮点计算,全面支持FP8、FP16、BF16乃至FP32等多种精度格式,并通过硬件级优化实现强浮点性能输出。这不仅意味着更高的数值精度保障,更标志着其真正具备了运行现代大语言模型(LLM)、视觉-语言模型(VLM)及多模态大模型的能力。
更重要的是,该架构并非简单地叠加浮点单元,而是基于DSP+DSA混合设计理念进行深度定制:DSP部分保留了高效的矩阵乘法引擎,擅长处理卷积神经网络(CNN)等结构;DSA部分则针对Transformer架构中频繁出现的Softmax、LayerNorm、Attention等操作进行了硬核加速,形成“软硬协同”的专用计算流水线。
这种架构组合使得“周易”X3既能兼顾传统CV任务效率,又能精准匹配大模型的核心计算特征,实现在不同工作负载下的灵活切换与最优性能释放。
在算力层面,“周易”X3单Cluster可配置4个Core,提供8~80 FP8 TFLOPS的可扩展算力,支持灵活裁剪以适应不同应用场景需求——从小尺寸IoT设备到高性能AI PC均可适配。
但真正的亮点在于其单Core高达256GB/s的带宽能力,这一指标超越当前多数移动端NPU水平。结合实测数据显示,在Llama2 7B模型的Decode阶段,有效带宽利用率甚至超过100%,背后正是得益于安谋科技自研的WDC(Weight Decompression Circuit)解压硬件加持。
WDC模块可在硬件层面实时完成压缩权重的解压,无需依赖主处理器干预,从而将等效带宽提升约15%-20%。这意味着即使在物理带宽不变的情况下,实际可用数据吞吐率大幅提升,直接缓解了“内存墙”问题。此外,WDC还支持多种量化方式,包括Tensor-Level、Channel-Level、Token-Level以及GPTQ等前沿方法,极大增强了模型部署灵活性。

如果说算力和带宽是“肌肉”,那么“周易”X3的另外两大核心创新——W4A8/W4A16计算加速模式与AIFF(AI Fixed-Function)硬件引擎,则是它的“神经系统”。
W4A8和W4A16是当前主流的大模型轻量化方案。它们能在保持较高推理精度的同时,将模型大小压缩至原体积的1/4左右,显著降低存储和传输成本。“周易”X3首次在NPU IP层级原生支持这些低比特计算模式,意味着:模型可以直接以压缩形式加载;硬件自动完成低比特乘加运算;不再需要额外的软件层转换开销。这一特性使得云端预训练好的大模型可以“一键迁移”至端侧设备,极大降低了落地门槛。
而AIFF+硬化调度器,则进一步打造了极致低负载、低延迟体验。
在多任务并发场景下,传统NPU往往依赖CPU进行任务分发与资源协调,造成CPU负载飙升,影响整体系统响应速度。“周易”X3引入了AI专属硬件引擎AIFF,配合专用硬化调度器,实现了:CPU负载降至0.5%以下;调度延迟极低,适合实时性要求高的应用(如语音助手、自动驾驶感知);支持任意优先级的任务调度策略,确保高优先级任务即时响应。例如,在手机同时运行语音识别、图像增强和文字生成时,AIFF可独立管理各任务队列,避免相互干扰,实现真正的“并行流畅体验”。
通过架构创新、算力带宽增强、创新硬件引擎加持,“周易”X3在多个关键指标上均实现质的飞跃:AIGC大模型能力相较X2提升10倍、CNN模型性能提升30%-50%、多核算力线性度达到70%-80%、Softmax/LayerNorm性能提升>10倍、FP16算力提升16倍、计算核心带宽提升4倍。
Compass平台:推动“从好用到用好”的端侧AI开发
在提供高性能硬件的同时,“周易”X3 NPU IP配套推出完善的Compass AI软件平台,通过软硬协同设计,致力于解决端侧AI开发中长期存在的“适配难、周期长、门槛高”三大痛点,帮助开发者实现从“能用”到“高效用好”的跨越。
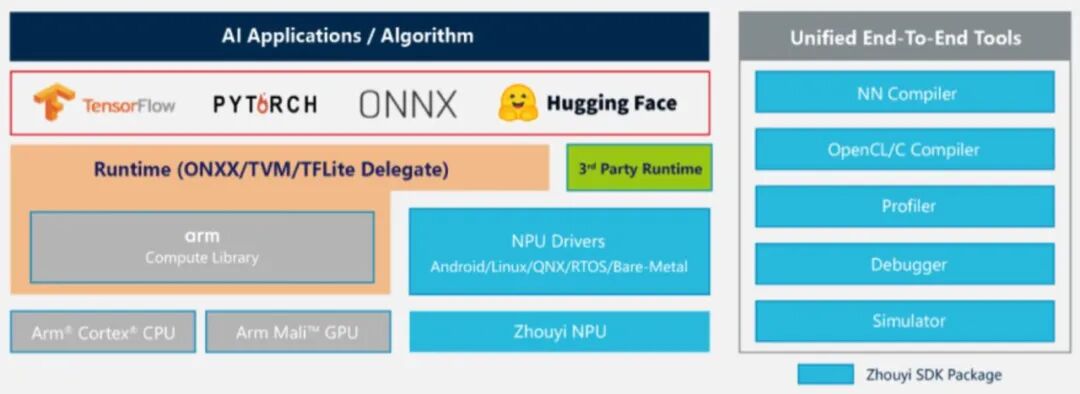
Compass平台覆盖模型开发、优化、部署和调试的全流程,其核心是集成化的神经网络编译器(NN Compiler),包含Parser(模型解析)、Optimizer(优化器)、GBuilder(代码生成器)及AIPULLM(大模型运行工具)四大模块,支持主流AI框架与前沿大模型的高效转化与自动化部署。
在兼容性方面,平台已支持超过160种算子与270多种模型,全面兼容TensorFlow、ONNX、PyTorch及Hugging Face等主流框架,并提供开箱即用的Model Zoo。尤为突出的是,通过AIPULLM工具链,Compass实现了对Hugging Face格式模型的“一键部署”,大幅降低大模型从云端迁移到端侧的工程门槛。
针对大模型推理的特殊需求,Compass平台提供业界领先的动态Shape支持能力,可高效处理任意长度的输入序列;同时支持Tensor-Level、Channel-Level、Token-Level等多种量化粒度,并集成GPTQ等大模型主流量化方案,确保在W4A8/W4A16等低比特模式下仍保持较高推理精度。平台亦明确支持LLM(大语言模型)、VLM(视觉-语言模型)、VLA(视觉-语言-动作模型)及MoE(混合专家)等新型架构。
为赋能深度定制开发,Compass平台提供多层次开放能力:
支持用户自定义算子开发与集成;
提供Bit精度软件仿真平台与丰富调试工具,实现白盒化性能分析与调优;
引入更易用的DSL(领域特定语言)算子编程接口,简化复杂算子实现;
开源Parser、Optimizer、Linux Driver、TVM适配层及内部IR格式等核心组件,允许客户基于平台构建自有模型编译器,实现差异化创新。
在系统层面,Compass平台兼容Android、Linux、RTOS、QNX等多种操作系统,并通过TVM/ONNX支持SoC异构计算架构,可高效调度CPU、GPU与NPU资源,最大化整机能效。
值得一提的是,Compass平台与“周易”X3硬件进行了深度协同设计。例如,AIFF硬件模块在设计阶段即结合软件使用场景,通过提升总线带宽、增加DMA outstanding能力等方式优化数据搬运效率;而软件端则针对多核架构提供模型切分策略,充分释放硬件并行潜力。这种双向协同,使得“周易”X3在实测中不仅实现了CNN模型30%~50%的性能提升,更在AIGC大模型任务上展现出显著优势。
“周易”X3:安谋科技“All in AI”战略的首个落子
“周易”X3 NPU IP的推出,标志着安谋科技正式全面转向“All in AI”战略,将AI置于其IP产品战略的核心。作为这一转向下的首款产品,“周易”X3不再局限于传统端侧推理任务,而是面向大模型时代重构架构,覆盖从AI手机、智能座舱到边缘加速卡和智能物联网设备的多元场景。
在智能汽车领域,它可同时支撑ADAS辅助驾驶与座舱多模态交互;在移动终端,支持本地运行1.5B级语言模型或Stable Diffusion等生成式应用;在边缘基础设施中,则为CNN与大模型混合负载提供高效算力。这种跨场景的适应性,反映出安谋科技对端侧AI需求演变的判断——未来芯片必须兼顾通用性、浮点能力和软件灵活性。
而“周易”X3的发布,也清晰传递出公司的战略重心转变:从过去以CPU+传统NPU为主的IP组合,转向围绕AI工作负载深度优化的全栈能力构建。这不仅是产品线的迭代,更是安谋科技在AI爆发期重新定义自身角色的关键一步。
 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP
天牛宝提示:文章来自网络,不代表本站观点。
相关文章



热点资讯



